- 사이킷런 소개
사이킷런은 파이썬 머신러닝 라이브러리 중 가장 많이 사용되는 라이브러리로, 머신러닝을 위한 다양한 알고리즘을 제공한다. 사이킷런에서 주로 사용되는 모듈은 다음과 같다.
| 분류 | 모듈명 | 설명 |
| 예제 데이터 | sklearn.datasets | 사이킷런에 내장되어 예제로 제공하는 데이터 세트 |
| 피처 처리 | sklearn.preprocessing | 데이터 전처리에 필요한 기능 제공(인코딩, 정규화, 스케일링 등) |
| sklearn.feature_selection | 알고리즘에 큰 영향을 미치는 피처를 우선순위대로 고르는 작업을 수행하는 기능 제공 | |
| sklearn.feature_extraction | 텍스트 데이터나 이미지 데이터의 벡터화된 피처를 추출하는데 사용됨 | |
| 차원 축소 | sklearn.decomposition | 차원 축소와 관련한 알고리즘을 지원하는 모듈 |
| 데이터 분리, 검증 | sklearn.model_selection | 교차 검증을 위한 학습용/테스트용 데이터 분리 |
| 평가 | sklearn.metrics | 분류, 회귀, 클러스터링, 페어와이즈(Pairwise)에 대한 다양한 성능 측정 방법 제공 |
| ML 알고리즘 | sklearn.ensemble | 앙상블 알고리즘(랜덤 포레스트, 에이다 부스트, 그래디언트 부스팅 등) 제공 |
| sklearn.linear_model | 선형회귀, Ridge, Lasso, 로지스틱 회귀 등 회귀 관련 알고리즘 제공 | |
| sklearn.naive_bayes | 나이브 베이즈 알고리즘(가우시안 NB, 다항분포 NB 등) 제공 | |
| sklearn.neighbors | 최근접 이웃 알고리즘(K-NN 등) 제공 | |
| sklearn.svm | 서포트 벡터 머신 알고리즘 제공 | |
| sklearn.tree | 의사 결정 트리 알고리즘 제공 | |
| sklearn.cluster | 비지도 클러스터링 알고리즘(K-평균, 계층형, DBSCAN 등) 제공 | |
| 유틸리티 | sklearn.pipeline | 피처 처리 등의 변환과 ML 알고리즘 학습, 예측 등을 함께 묶어서 실행할 수 있는 유틸리티 제공 |
- 사이킷런에 내장된 예제 데이터 세트
| API 명 | 설명 |
| datasets.load_boston() | 회귀 용도이며, 미국 보스턴 집 가격에 대한 데이터 세트 |
| datasets.load_breast_cancer() | 분류 용도이며, 위스콘신 유방암 악성/음성 데이터 세트 |
| datasets.load_diabetes() | 회귀 용도이며, 당뇨 데이터 세트 |
| datasets.load_digits() | 분류 용도이며 0에서 9까지 숫자의 이미지 픽셀 데이터 세트 |
| datasets.load_iris() | 분류 용도이며, 붓꽃의 종류 데이터 세트 |
일반적으로 사이킷런에 내장된 예제 데이터 세트는 Bunch클래스로 되어 있고, Bunch클래스는 파이썬의 딕셔너리와 형태가 비슷하다.
from sklearn.datasets import load_iris
iris = load_iris()
print(type(iris))
print(iris.keys())
실행 결과

- data는 피처의 데이터 세트를 가리킨다.
- target은 분류 시 레이블 값, 회귀일 때는 결과값 데이터 세트이다.
- target_names는 개별 레이블의 이름을 나타낸다.
- feature_names는 피처의 이름을 나타낸다.
- DESCR은 데이터 세트에 대한 설명과 각 피처의 설명을 나타낸다.
- filename은 파일명을 나타낸다.
분류(Classification)와 회귀(Regression)은 대표적인 지도학습(Supervised Learning) 방법이다. 지도학습은 학습을 위한 다양한 피처(feature)와 분류 결정값인 레이블(Label) 데이터로 모델을 학습한 뒤, 별도의 테스트 데이터 세트에서 피처만 보고 레이블 값을 에측한다. 즉, 피처는 데이터 세트에서 속성을 의미하고, 레이블은 결정값을 의미한다.
예를 들어, 위에서 불러온 붓꽃 데이터 세트에서는 data가 붓꽃 데이터 세트를, target이 결과값(붓꽃 품종을 숫자로 나타낸 값)을, target_names가 붓꽃 품종명을, feature_names는 붓꽃의 속성명을 의미한다.
print('target:\n', iris.target)
print('\ntarget_names:\n', iris.target_names)
print('\nfeature_names:\n', iris.feature_names)실행 결과
0은 setosa, 1은 versicolor, 2는 virginica를 의미하는 것이고, data는 sepal length, sepal width, petal length, petal width에 대한 데이터 값이 들어 있는 데이터 세트이다.
붓꽃 데이터 세트를 DataFrame으로 불러오는 과정은 다음과 같다.
import pandas as pd
# data에 속성값 저장, columns에 속성명 저장
iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
# data에는 label값이 없으므로, label열에 target을 추가
iris_df['label'] = iris.target
# apply lambda식을 이용하여 label명에 target_names 추가
iris_df['label_name'] = iris_df['label'].apply(lambda x : iris.target_names[x])
# DataFrame 출력
iris_df.head()실행 결과
- 사이킷런의 지도학습 수행과정
1. 학습/테스트 데이터 세트 분리 - train_test_split()
sklearn.model_selection 모듈에서 train_test_split을 로드한다. 첫 번째 파라미터로 피처 데이터 세트, 두 번째 파라미터로 레이블 데이터 세트를 입력받는다. 그 이외의 파라미터는 선택적으로 입력받을 수 있다.
test_size: 전체 데이터에서 테스트 데이터 크기를 얼마로 샘플링할 것인가를 결정한다. default값은 0.25(25%)이다.
train_size: 전체 데이터에서 학습용 데이터 크기를 얼마로 샘플링할 것인가를 결정한다. 보통 test_size를 입력하므로 train_size는 잘 입력하지 않는다.
shuffle: 데이터를 분리하기 전에 미리 섞을지를 결정한다. 데이터를 분산시키는 것이 효율적으로 학습을 시킬 수 있고, default값이 True이므로 마찬가지로 잘 입력하지 않는다.
random_state: 호출할 때마다 동일한 학습/테스트용 데이터 세트를 생성하기 위해 주어지는 난수 값이다. random_state 값을 지정하지 않으면 수행할 때마다 무작위로 데이터를 분리하므로 다른 학습/테스트용 데이터를 생성한다.
train_test_split()은 순차적으로 학습용 데이터의 피처 데이터 세트, 테스트용 데이터의 피처 데이터 세트, 학습용 데이터의 레이블 데이터 세트, 테스트용 데이터의 레이블 데이터 세트를 튜플 형태로 반환한다. 피처 데이터 세트에는 일반적으로 변수 X, 레이블 데이터 세트에는 변수 y를 사용하고 학습용에는 train, 테스트용에는 test를 붙인다.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 붓꽃 데이터 세트 불러오기
iris = load_iris()
# 학습 피처, 테스트 피처, 학습 레이블, 테스트 레이블 데이터 세트를 순차적으로 저장
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=5)
print('전체 피처 데이터 shape:', iris.data.shape)
print('학습용 피처 데이터 shape:', X_train.shape)
print('테스트용 피처 데이터 shape:', X_test.shape)
print('학습용 레이블 데이터 shape:', y_train.shape)
print('테스트용 레이블 데이터 shape:', y_test.shape)실행 결과
전체 150개 데이터 중에서 학습용으로 80%, 테스트용으로 20%가 잘 분리된 것을 확인할 수 있다.
2. 모델 학습 - fit()
학습 데이터를 기반으로 ML 알고리즘을 적용해 모델을 학습시킨다. 대표적인 지도학습인 분류와 회귀 모두 fit()을 이용해 간단하게 모델을 학습시킬 수 있다. 예시로 DecisionTreeClassifier 모델에 대하여 위 단계에서 분리한 학습용 데이터 세트를 학습시키는 과정은 다음과 같다.
# DecisionTreeClassifier 모델 생성
from sklearn.tree import DecisionTreeClassifier
# DecisionTreeClassifier 객체 생성
tree = DecisionTreeClassifier(random_state=5)
# 모델 학습 수행
tree.fit(X_train, y_train)
3. 예측 수행 - predict()
학습된 ML 모델을 이요해 테스트 데이터의 분류를 예측한다. 예측도 학습과 마찬가지로 predict()를 이용하여 간단하게 예측을 진행한다. 위에서 학습한 모델에 대한 예측을 하는 과정은 다음과 같다.
# 테스트용 피처 데이터 세트에 대하여 예측 수행
pred = tree.predict(X_test)
pred실행 결과

각 피처에 대하여 예측을 수행한 결과값이 ndarray로 저장된 것을 확인할 수 있다.
4. 평가
위의 단계에서 예측된 결과값과 데이터의 실제 결과값을 비교하여 ML 모델 성능을 평가한다. 정확도 측정을 위해 sklearn.metrics의 accuracy_score() 함수를 사용할 수 있다. 평가지표에는 정확도 이외에도 정밀도, 민감도(재현율), F1 Score 등이 존재한다.
from sklearn.metrics import accuracy_score
# 테스트용 레이블 데이터 세트에 대한 예측값의 정확도
print(accuracy_score(y_test, pred))실행 결과
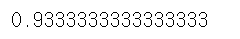
테스트 데이터로 예측을 수행한 결과 정확도는 약 93.33%인 것을 확인할 수 있다.
'머신러닝(MachineLearning) > 사이킷런(scikit-learn)' 카테고리의 다른 글
| 교차검증 (0) | 2022.07.22 |
|---|