- DataFrame [ ] 연산자
DataFrame의 [ ] 안에 열(column) 이름을 넣어 원하는 열의 데이터만 추출할 수 있다. 여러 개의 열의 데이터를 추출하고자 할 때는 [ ] 안에 열 이름들을 다시 [ ]로 묶어 리스트형으로 만들어줘야 한다.
import pandas as pd
# 타이타닉 데이터 파일 불러오기
titanic_df = pd.read_csv('train.csv')
# 타이타닉 데이터에서 Name 열과 Age 열만 추출하기
filtered_df = titanic_df[['Name', 'Age']]
filtered_df.head(3)실행 결과

- DataFrame의 iloc[ ] 연산자
iloc[ ] 는 위치 기반 인덱싱으로 [ ] 안에 행, 열 값으로 정수가 입력된다.
# 1행 4열의 데이터 반환
titanic_df.iloc[0, 3]실행 결과
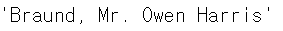
iloc[ ] 에 위치값(정수)이 아닌 명칭(문자열)을 입력하면 오류가 발생한다. 또한, 슬라이싱과 팬시 인덱싱은 제공하지만 명확한 위치 인덱싱이 사용되어야 하기 때문에 불린 인덱싱은 제공되지 않는다.
- DataFrame의 loc[ ] 연산자
loc[ ] 는 명칭 기반 인덱싱으로 [ ] 안에 행 위치에는 DataFrame의 Index값, 열 위치에는 열(column) 이름이 입력된다.
titanic_df.loc[0, 'Name']실행 결과
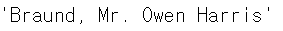
loc[ ] 에서 슬라이싱을 할 때 주의점은 일반적인 슬라이싱 범위(시작값 ~ 종료값 - 1)와 달리 loc[ ] 에서는 시작값부터 종료값까지 모두 추출된다는 것이다. 그 이유는 Index의 명칭이 정수가 아닐 수도 있어서 -1을 할 수 없기 때문이다.
titanic_df.iloc[0:1, 3]실행 결과

titanic_df.loc[0:1, 'Name']실행 결과
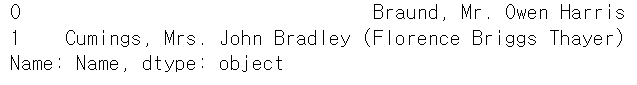
- 불린 인덱싱
판다스에서의 불린 인덱싱도 넘파이에서의 불린 인덱싱과 비슷하게, [ ] 안에 조건을 넣어 원하는 데이터를 추출할 수 있다. 여러 개의 조건을 복합적으로 적용할 수도 있는데, And 조건은 '&', Or 조건은 '|', Not 조건은 '~'기호로 표시해주면 된다. 이때, 각 조건은 ( )로 묶어서 나타내야 한다. 예를 들어 타이타닉 탑승자 중에서 나이가 40이하이고 성별이 남성이거나, Pclass가 1이 아닌 사람들의 데이터를 추출하는 코드는 다음과 같다.
titanic_df[(titanic_df['Age'] <= 40) & (titanic_df['Sex'] == 'Male') | ~(titanic_df['Pclass'] == 1)]실행 결과

이때, 각 조건들이 복잡하다면 아래와 같이 각 조건들을 변수에 할당하여 간단하게 나타낼 수 있다.
cond1 = titanic_df['Age'] <= 40
cond2 = titanic_df['Sex'] == 'Male'
cond3 = titanic_df['Pclass'] == 1
titanic_df[cond1 & cond2 | ~cond3]
'머신러닝(MachineLearning) > 판다스(Pandas)' 카테고리의 다른 글
| DataFrame 결손 값 처리하기, apply lambda (0) | 2022.07.14 |
|---|---|
| DataFrame의 정렬, Aggregation, groupby (0) | 2022.07.13 |
| Index 객체 (0) | 2022.07.07 |
| DataFrame 데이터셋 수정하기 (0) | 2022.06.26 |
| DataFrame으로 데이터 불러오기 (0) | 2022.06.24 |